
“国内在 AI 数据安全方面存在一定的限制和监管,我们一般了解到的大模型聚焦于国内企业和少数国外头部企业。但是,实际参与大模型竞争的公司及模型数量远不止此。本文对大模型全球权威基准测试(Benchmark)进行梳理,整理出61个全球知名大模型。希望为大家提供一个认识全球大模型的客观视角。通过引导读者查阅权威基准测试内容,帮助大家客观认知全球大模型的竞争格局。”
一 全球知名的大模型基准测试
2022年,OpenAI的ChatGPT引爆了大家的眼球。2023年,各家大模型在不同的时间节点及测试数据集上,纷纷自称“遥遥领先”!
如何科学客观评价大模型的性能?
目前有三类评估大模型的基准测试。第一类是以ImageNet为代表的特定任务的数据集。第二类是以GLUE、SuperGLUE、DecaNLP、SentEval为代表的新的多场景评测基准。第三类是以HELM、 GEM、XTREME、GEMv2为代表的综合评测基准。
- 第一类评测基准的局限性是,过分聚焦于某一类任务,评估维度较单一。
- 第二类基准为每个模型分配一个分数向量,以度量一组场景的准确性。在某些情况下,这些基准测试还提供了一个汇总分数(例如GLUE分数,为每个组成场景的准确率的平均值)。
- 第三类评测基准中,以HELM为例,为每个模型分配一个分数矩阵:对每个场景,检测7个指标(例如准确性,校准,稳健性,公平性,效率等),从而把从单一的准确性评估拓展到多个维度的评估。
- 综合评测基准测试:
HELM(Holistic Evaluation of Language Models):由斯坦福大学大模型中心推出。(官网地址:https://crfm.stanford.edu/helm/latest/?)
- 多场景基准测试:
GLUE(General Language Understanding Evaluation):由纽约大学、华盛顿大学、DeepMind等机构联合推出。(官网地址:https://gluebenchmark.com/tasks) SuperGLUE(Super General Language Understanding Evaluation):以GLUE为风格的新基准,具有一套新的更难的语言理解任务集、软件工具箱和公共排行榜。(官网地址:https://super.gluebenchmark.com/)
- 数据集基准测试:
ImageNet:一个计算机视觉数据集,由斯坦福大学的李飞飞教授带领创建。
SQuAD(Stanford Question Answering Dataset):一个阅读理解数据集,由斯坦福大学于2016年推出。
SNLI(The Stanford Natural Language Inference (SNLI) Corpus):斯坦福自然语言推理(SNLI)语料库。
二 HELM 大模型排行榜
2022年11月,斯坦福大学大模型中心(官网地址:https://crfm.stanford.edu/helm/latest/?)筛选了全球30个主流大模型,进行了全方位的评测(少数大模型因不具备条件,未测评所有场景和指标)。
HELM测评包含了16个场景和7类指标。
场景由<任务,领域,语言>三元组表示,包括6个用户任务(问题回答,信息检索,内容总结等),多个领域(新闻,图书等),语言仅支持英语和英语的方言变种。
7类指标包括准确性,校准性,鲁棒性,公平性,偏差,有害性,效率等。
语言类大模型能力广泛且强大,拓宽评估范围是NLP(Natural Language Processing,自然语言处理)的趋势。
从使用像SQuAD这样的个别数据集到小规模的数据集集合,如SuperGLUE,再到大规模的数据集合,如GPT-3评估套件,Eleuther AI LM Harness和BIGBench。
然而,任何一种测评都不能包含所有的语义场景及评估指标。因此,HELM致力于提供一个较为全面的评估基准。HELM采用自上而下的分类方案,并明确了主要场景和及其度量标准。
值得一提的是,智谱AI的GLM-130B,在目前HELM的全面评估中是亚洲唯一入选的大模型。

2022斯坦福大学大模型中心对国际30个大模型的测评表
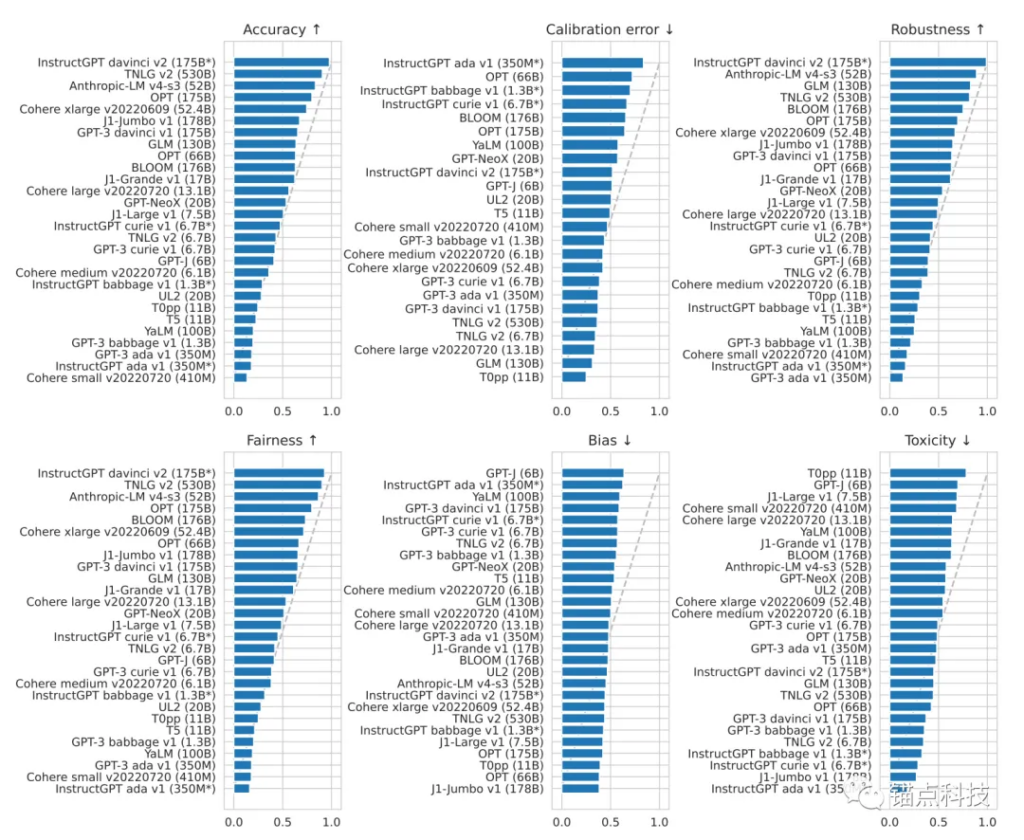
30个大模型在6个核心指标下的性能图
中国智谱AI的GLM-130B 在广泛流行的英文基准测试中的性能明显优于 GPT-3 175B(davinci),而相较于OPT-175B 和 BLOOM-176B 没有观察到性能优势。在相关基准测试中,GLM-130B 性能始终显著优于最大的中文语言大模型 ERNIE 3.0 Titan 260B。
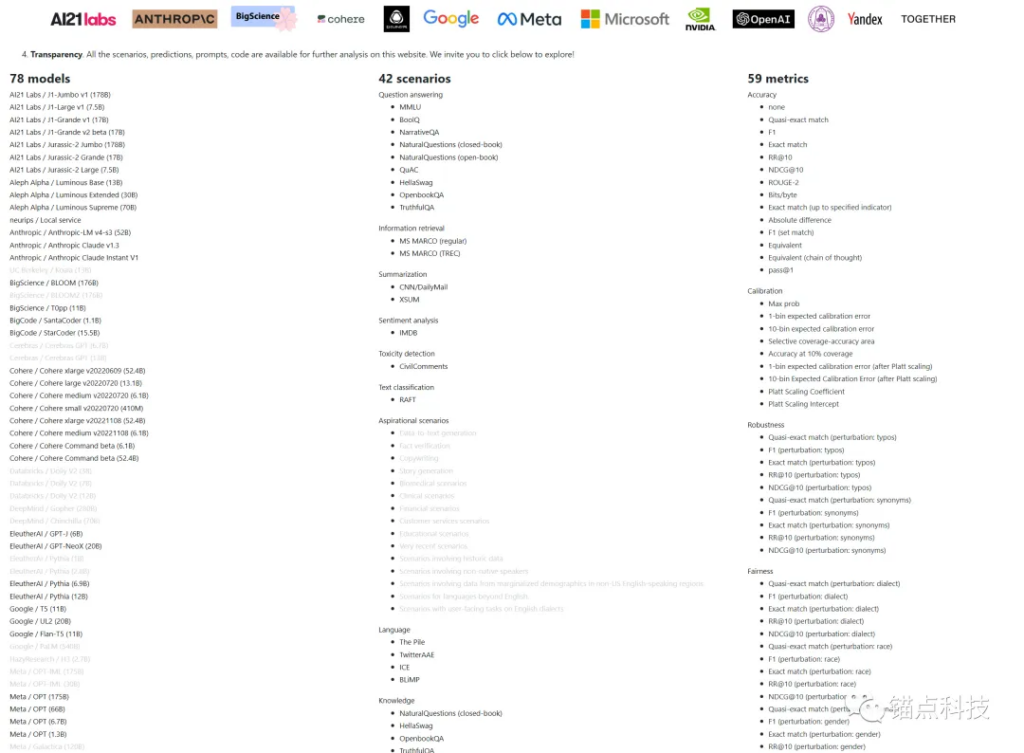
2023年扩展的HELM评测基准
三 HELM 大模型排行榜
GLUE (the General Language Understanding Evaluation benchmark 官网:https://gluebenchmark.com) 是用于对英文自然语言理解任务进行训练、校验和测试的数据集。
GLUE是自然语言处理领域的权威排行榜之一,包含十一项NLU任务,语言均为英语。
GLUE涉及自然语言推断、文本蕴含、情感分析、语义相似等多个任务。像BERT、XLNet、RoBERTa、ERINE、T5等知名模型都会在此基准上进行测试。
该榜单由纽约大学、华盛顿大学、DeepMind等机构联合推出,长期被视作评估NLP研究进展的行业标准。
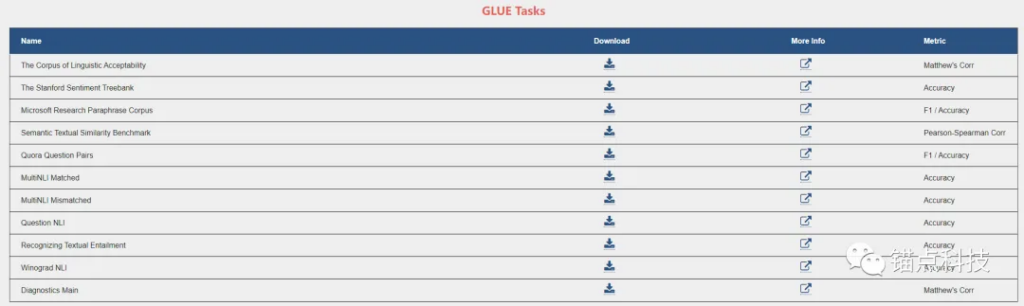
GLUE评测基准的任务集
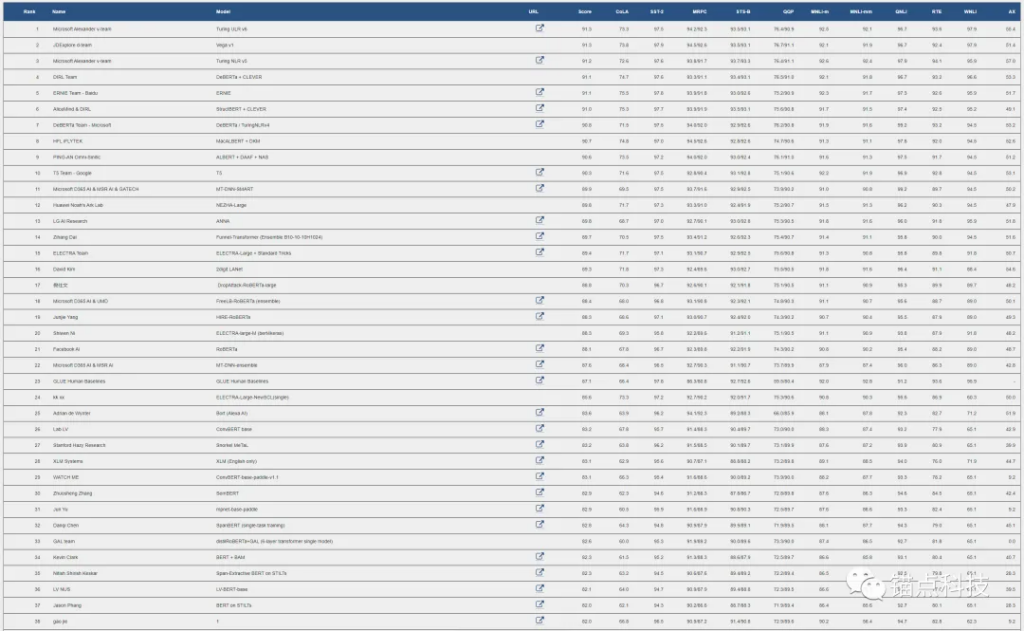
GLUE评测榜单
通过GLUE评测基准,我们能看到全球前88名的大模型的各项评测数据及总的评分数据。
四 C-Eval 中文大模型排行榜
C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的面向中文语言模型的综合性考试评测集,包含13948道多项选择题,涵盖52个不同学科和四个难度级别(初中、高中、大学和专业),是对模型潜力判断具权威性的大模型榜单之一。(官网地址:https://cevalbenchmark.com/static/leaderboard_zh.html)
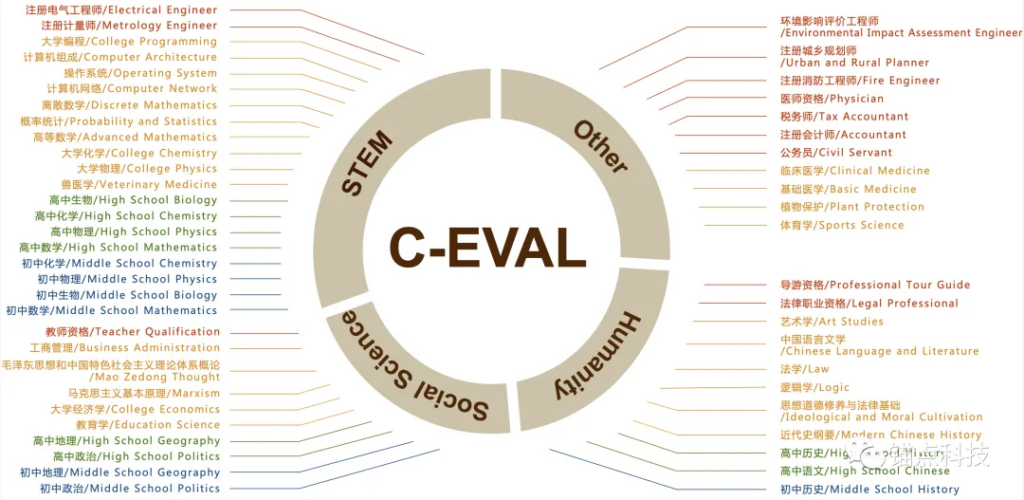
C-Eval测试集
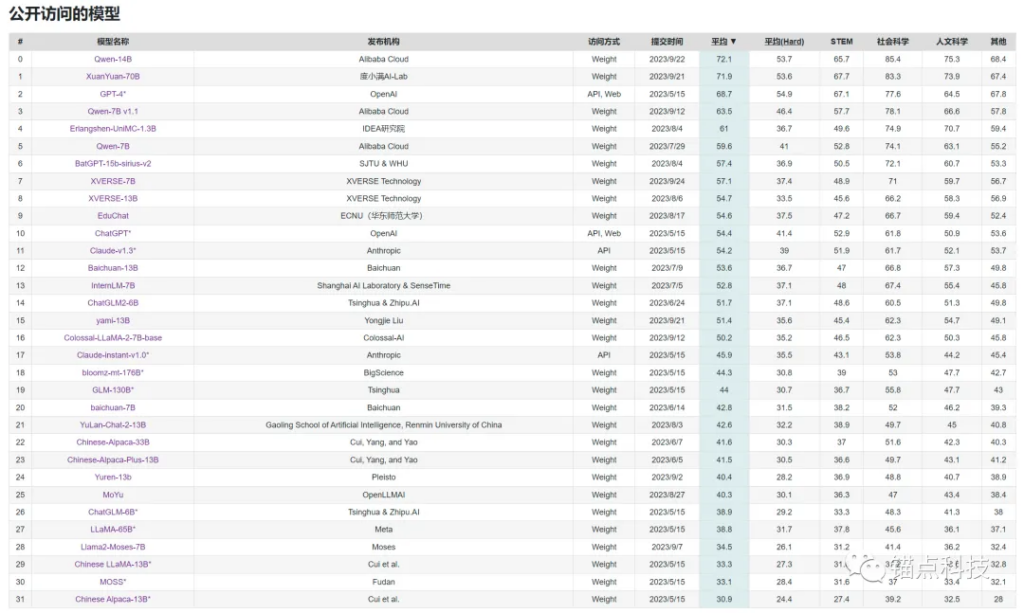
C-Eval 公开访问模型排行榜
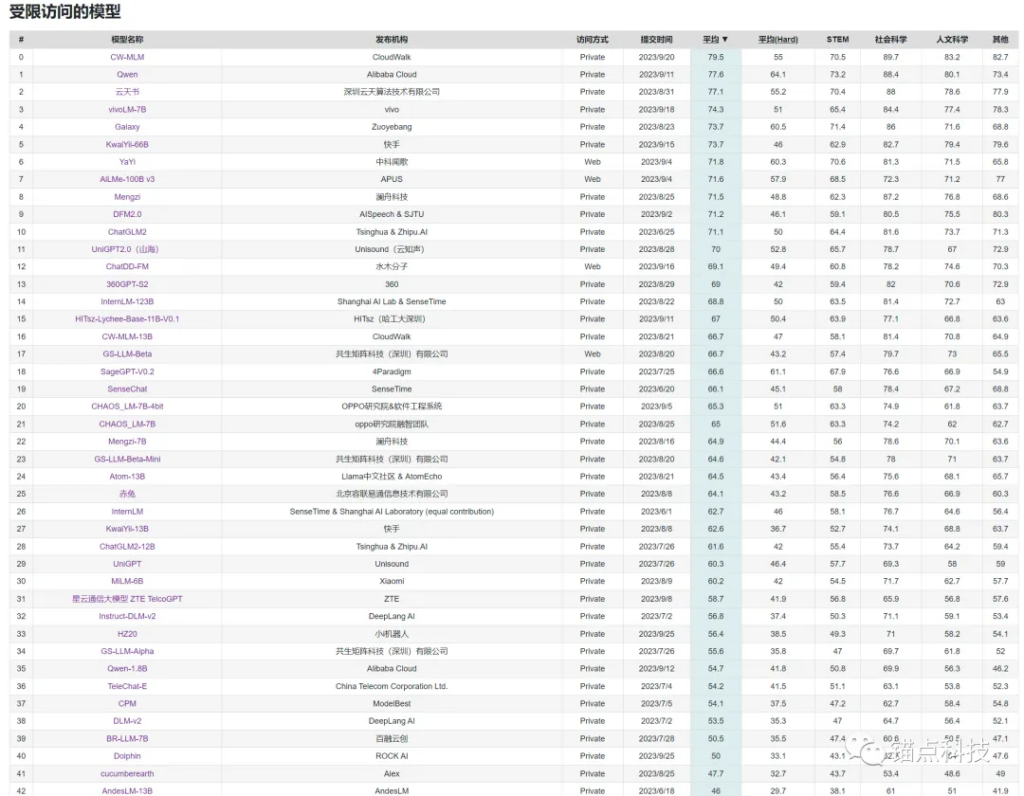
C-Eval 受限访问模型排行榜
C-Eval的出现在一定程度上缓解了中文社区大模型研发中,中文语义场景评价基准较少,质量不高的问题。
五 CLUE 中文大模型排行榜
CLUE是目前国内较权威的中文自然语言理解评测基准之一。(官网地址:https://www.cluebenchmarks.com/classification.html)CLUE的分类榜主要任务集列表如下:
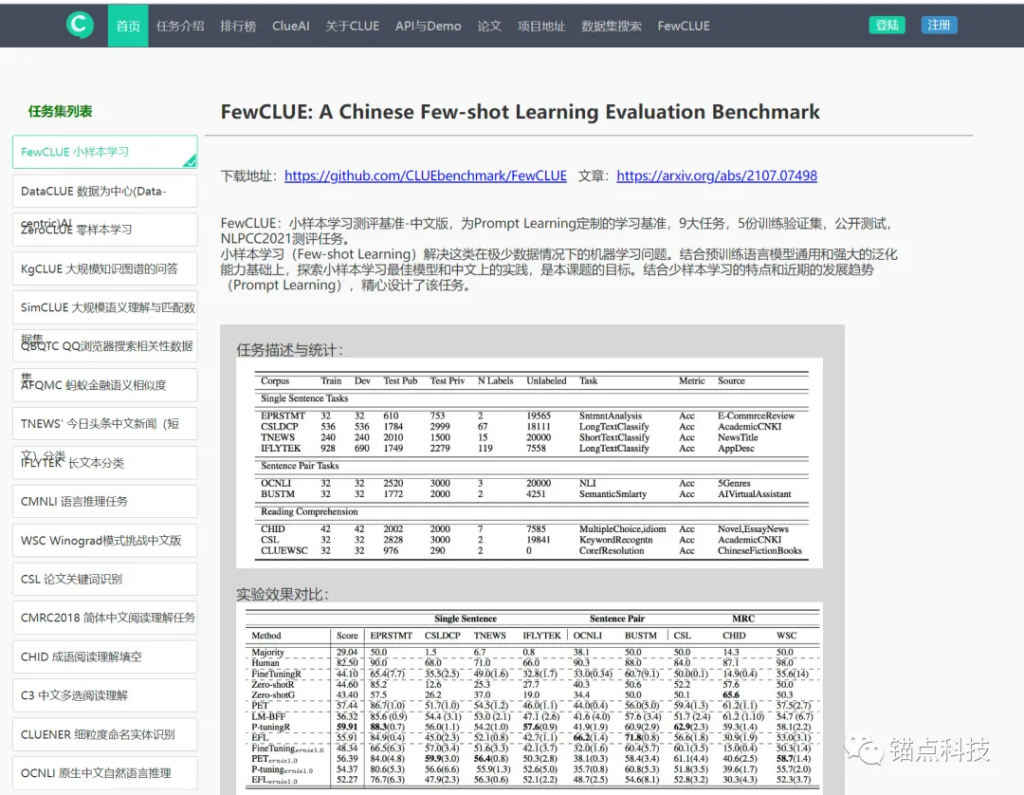
CLUE是第一个大规模的中文语言评估基准。 CLUE评估基准包括了以下能力:(1)覆盖了9种句子分类、机器阅读理解任务,不同的困难水平、不同的大小和形式;(2)提供了一个大的预训练中文语库,214G文本,约760亿中文词语;(3)提供了一个语言学家创建的诊断评估数据集;(4)提供了自动评估工具,及在线排行榜。
大量国内外互联网公司、高校以及个人参与到刷榜行列中。在CLUE的19个榜单中,以CLUE1.1总排行榜为例,目前CLUE1.1总排行榜已收录2994项评测结果。
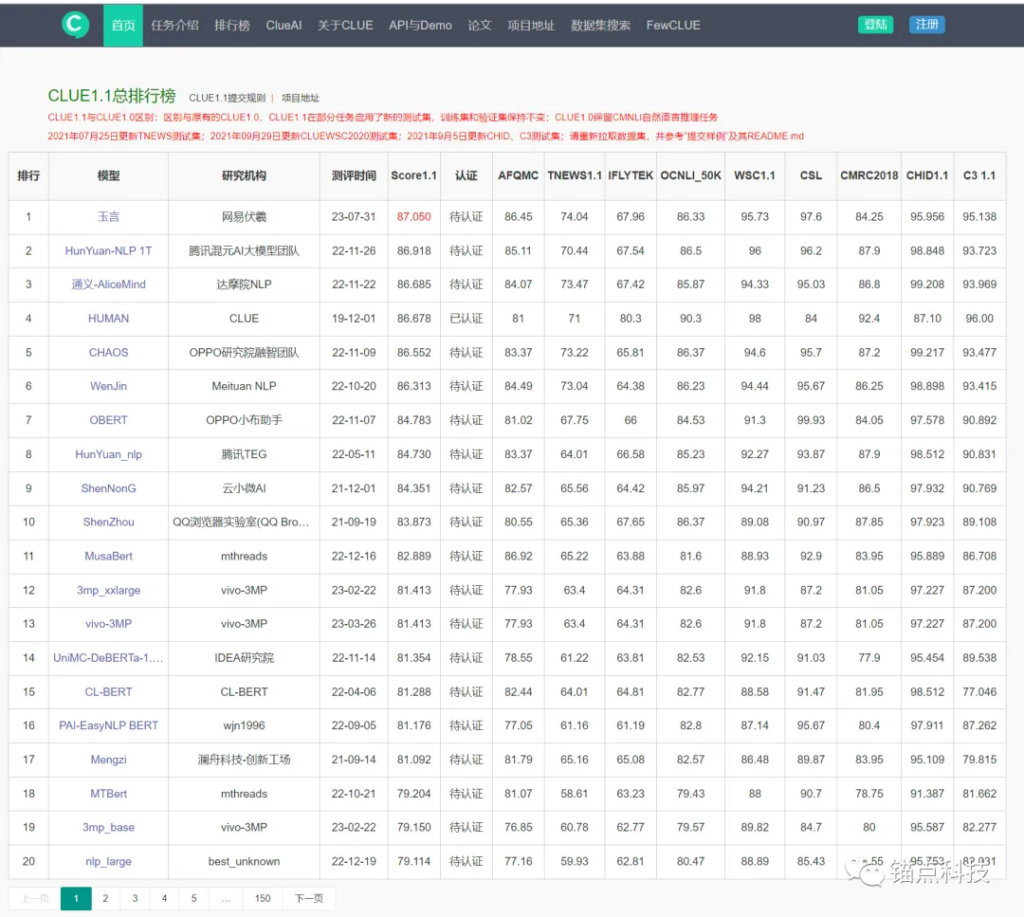
CLUE1.1总排行榜
六 全球主流大模型梳理
通过对HELM等相关基准测试,大模型排行榜进行梳理,本文梳理出61个全球主流大模型,并对全球大模型的竞争格局进行分析。
- 国外大模型分为美国大模型阵营和其他国家大模型阵营。国内大模型分为头部企业大模型阵营和其他企业大模型阵营。
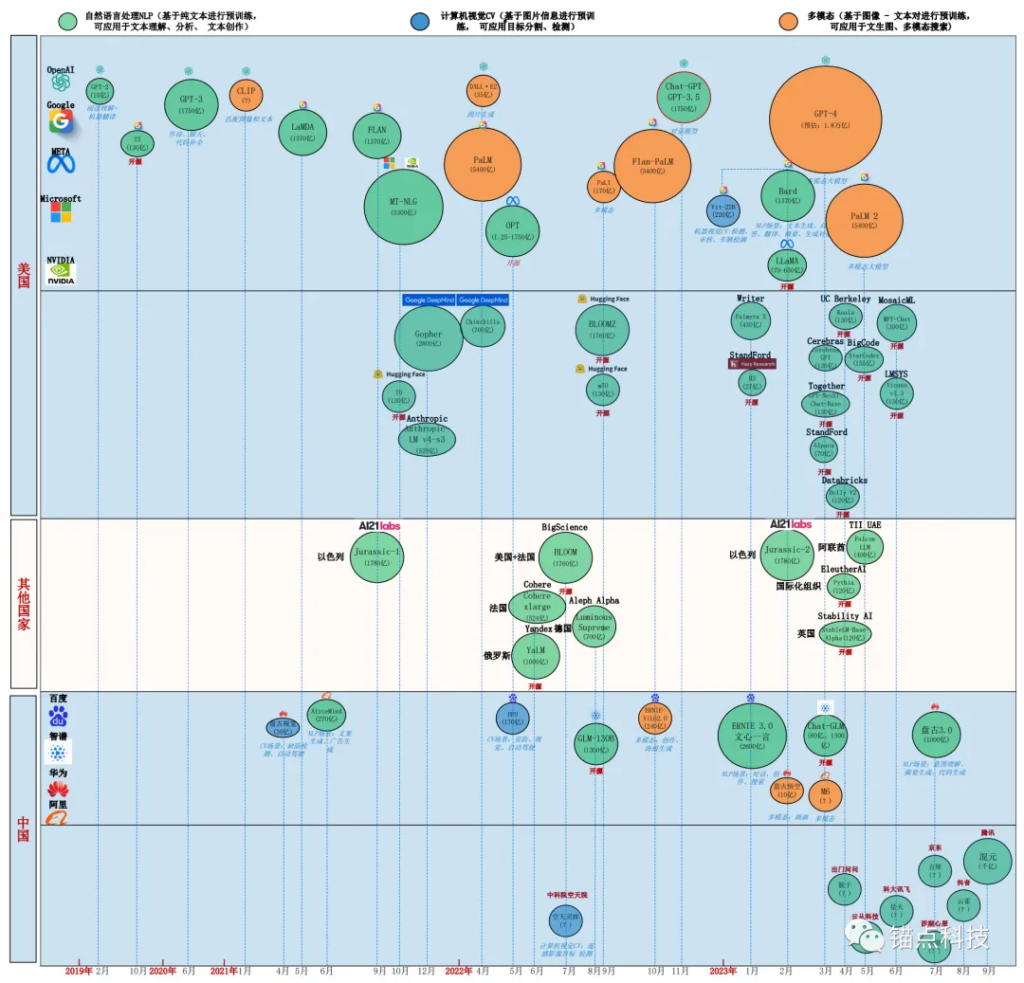
全球大模型全景图(2023年10月)
- 从整体上看,以美国为代表的企业/学术机构,无论是大模型的数量、大模型的规模、大模型的开源贡献度、大模型的算法原创性,都具备绝对的优势!
- 值得一提的是,美国以Meta、Hugging Face、Google、Standford为代表的企业/科研机构,为了防止大模型头部企业的垄断,在开源上,做出了很大的贡献。其中不乏千亿规模的开源大模型。
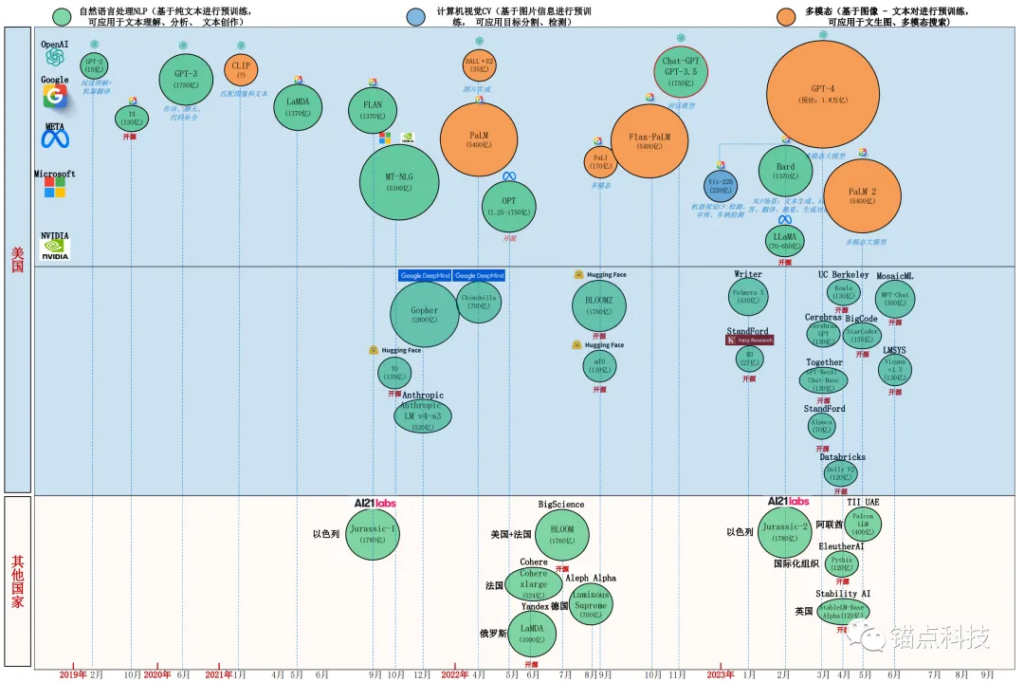
国外大模型全景图(2023年10月)
- 除美国的其他外国公司,参与大模型的节奏靠后,模型的数量、质量、开源程度都与美国存在较大差距。各个国家参与大模型的公司数量并不多,从侧面证明大模型的参与门槛较高。大模型的竞争,不仅需要本国具备较强研发实力的AI企业,而且需要有较强的学术机构参与。
- 来自以色列的J1大模型在千亿级别的HELM测评基准中表现相对亮眼。而来自俄罗斯的YaLM大模型在部分测评中,其性能还比不上参数规模为其1/10的大模型。
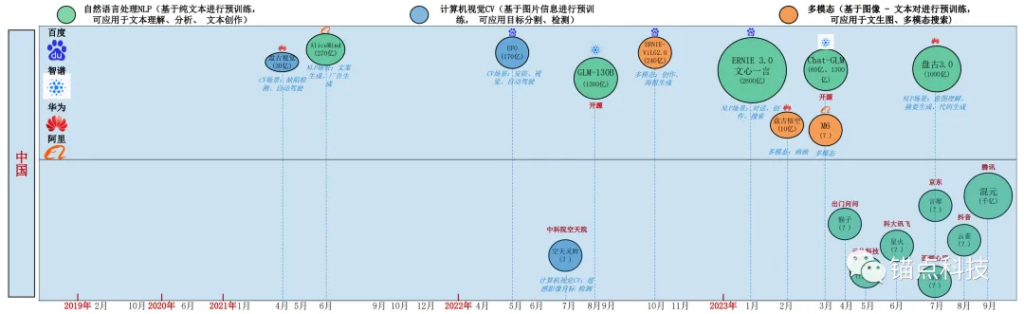
- 从大模型的数量和参数规模来看,中国为全球AI大模型的重要参与方。但是从HELM的评测来看,除了智谱的GLM大模型,国内剩下的企业的大模型,还未被国外权威机构纳入考察评测范围。